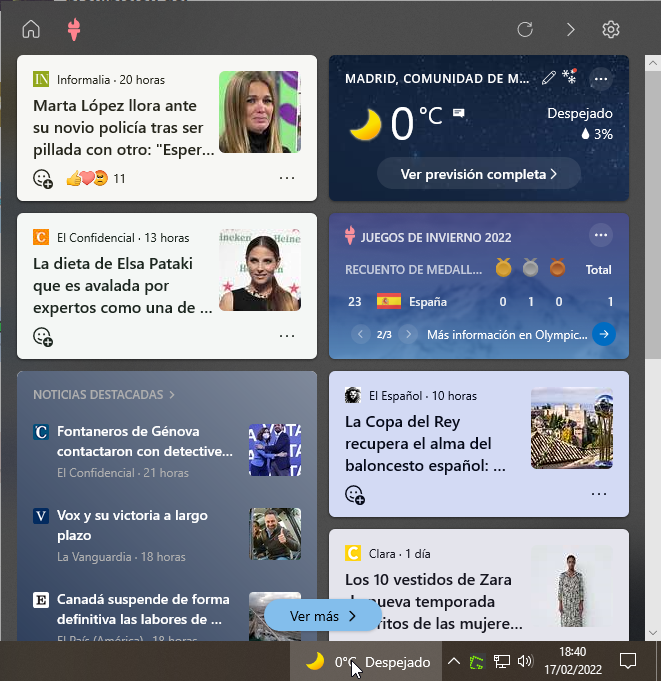
Explicamos en esta entrada cómo quitar el botón <<deportes>> del cuadro de búsqueda de la barra de tareas deshabilitando la funcionalidad de información destacada de búsqueda. Y es que como viene siendo habitual, Microsoft activa funcionalidades con las actualizaciones sin el consentimiento previo del usuario. Este botón dentro de la…
TI a todos los niveles