Introducción.
Hoy os presento una práctica nueva que consiste en implementar un intérprete de instrucciones del lenguaje de programación
BASIC. La práctica la tuve que realizar para la asignatura «Tecnología de Objetos» de la ingeniera superior y la comparto con todos vosotros porque es un ejercicio completo y, de necesitar algo similar, lo más seguro es que os inspire u os sirva para compararla con vuestra solución ya implementada.
Es importante resaltar dos aspectos. Primero: se trata de un intérprete y no de un compilador, por lo que los programas BASIC utilizados serán intepretados ejecutando una tras otra cada instrucción del programa. Segundo: se trabaja sobre un lenguaje BASIC reducido ya que el lenguaje original posee multitud de tipos de datos y de instrucciones. El tipo de dato con que trabajar será el de los enteros y las sentencias a implementar serán REM, DIM, LET, PRINT, INPUT y GOTO. De todas formas, se requiere diseñar el intérprete de forma que sea fácilmente extensible a nuevos tipos de datos (como números fraccionales y cadenas de caracteres) así como a nuevas intrucciones (saltos condicionales, bucles, etc…).
Consideraciones.
A la hora de abordar la práctica surgen una serie de aspectos que dejan cierta libertad al programador, por lo que se especifican todos ellos para aclarar el enfoque utilizado y no irse por las ramas:
- Todas las etiquetas e identificadores siguen la regla de identificadores de la gramática [a-z]+. Por lo que las etiquetas comienzan por dos puntos (:) seguidos de una o más letras minúsculas y los identificadores de variable serán de al menos de una letra minúscula. Ejemplos de etiquetas e identificadores válidos:
:etiqueta
:bucle
:otraetiqueta
variable
variableuno
Ejemplos de identificadores no válidos:
: etiqueta
:BUCLE
:otra etiqueta
_variable
variable1
- Las expresiones tras una expresión de asignación en una instrucción LET pueden concatenarse con los operadores ariméticos (+, –, * y /) y aunque no se haga uso de paréntesis las operaciones son asociativas por la izquierda sin que exista prioridad de operadores. Es decir; se irá operando con todos los operadores comenzando por la izquierda con los dos primeros operandos (no existen operadores unarios) y ese resultado, se utilizará con el siguiente operador y operando y así sucesivamente. Ejemplo:
LET var = 5 + 7 * 2
REM Almacenará en var el valor 24 (5+7=12 y 12*2=24)
- Las expresiones soportan tanto valores explícitos enteros como identificadores de variables declaradas e inicializadas previamente. Si se opera con una variable declarada pero sin inicializar se obtendrá un error en tiempo de ejecución y el intérprete abortará su ejecución.
- Los programas BASIC escritos se guardarán en un fichero de texto plano con extensión .BAS o .bas para pasarlos como argumento al programa intérprete. Debe de ser un programa válido sino se indicarán los errores durante el proceso de análisis.
- Las sentencias no soportan espaciados inútiles. Esto significa que un fichero correcto no contendrá tabulaciones al principio ni espacioes en blanco tanto al principio de una instrucción como al final de la misma en una línea. El analizador también considerará como un error si separando los componentes de una instrucción (como entre un identificador y un operador) hay más de un espacio.
- El proceso de interpretación será sencillo: se vuelca todo el contenido del fichero del código fuente, se analiza la primera línea para luego ejecutar la instrucción obtenida y después se analiza la segunda línea ejecutándola a continuación de la primera y así sucesivamente.
- Las instrucciones de salto incondicional GOTO se ejecutan una única vez. De esta forma se ejecutan de forma finita y se evitan los bucles infinitos que un usuario pueda hacer, ya que al ser un lenguaje interpretado sólo se puede saltar a una instrucción anterior, ya que una posterior sería desconocida (aún no se analizó).
Puesta en marcha; Uso del intérprete.
Para utilizar el intérprete de BASIC se ha de situar a través de la consola de comandos del sistema operativo en el directorio dónde se encuentre el ejecutable para trabajar con mayor comodidad. Para la demostración se utilizará un programa similar al presentado en el enunciado de la práctica, escrito con un editor de texto plano como Vim, Emacs o nano:
REM multiplica
DIM operandouno
DIM operandodos
DIM resultado
:bucle INPUT "Primer operando: ", operandouno
INPUT "Segundo operando: ", operandodos
LET resultado = operandouno * operandodos / 2
PRINT "Resultado: ", resultado
GOTO bucle
 |
| Ilustración 1: Creación del código fuente de un programa BASIC con un editor de texto plano. |
El programa se guarda con un nombre significativo más la extensión .bas. Para el programa anterior se eligió el nombre programa.bas y se guardó en el mismo directorio que el ejecutable.
Para interpretar el programa es suficiente con ejecutar el binario del programa pasándole como primer y único argumento la ruta (relativa o absoluta) al fichero con código fuente BASIC y extensión .bas.
 |
| Ilustración 2: Ejecución correcta del intérprete BASIC. |
En el caso de no proporcionar un fichero fuente como parámetro o varios, se mostrará en el primero de los casos un error con las posibles causas y, en caso del segundo, una advertencia conforme se tomará como fichero fuente el primero de los argumentos y el resto se desecharán.
También saltará un error en caso de que la extensión del fichero fuente no sea la adecuada, independientemente del contenido.
 |
| Ilustración 3: Error al no pasar el fichero fuente como parámetro al intérprete. |
 |
| Ilustración 4: Paso de más de un fichero con código fuente como parámetros al intérprete. |
 |
| Ilustración 5: El fichero de código fuente carece de extensión .BAS. |
Al ejecutar el programa correcto, se va analizando y ejecutando cada una de las líneas (instrucciones) a partir del código fuente BASIC, solicitando los operandos que proceda, imprimiendo los mensajes por pantalla etc… Nótese que la división es entera y que el salto sólo se ejecuta la primera vez.
 |
| Ilustración 6: Ejecución correcta de un programa BASIC hasta su finalización. |
A continuación se muestra un ejemplo de error en tiempo de ejecución, como puede ser una división por cero o que el usuario introduzca caracteres en vez de un número entero. Tras un error de este tipo el programa aborta su ejecución.
 |
| Ilustración 7: Ejemplo de error en tiempo de ejecución tras leer un valor incorrecto de teclado. |
El analizador señala todos los errores encontrados en una línea determinada antes de que sea interpretada en cuestión. Espacios en blanco, instrucciones en minúscula y comas olvidadas son errores de los más frecuentes a la hora de codificar un programa. El intérprete muestra un error descriptivo por pantalla junto con la línea del fichero en que se encuentra el error y aborta la ejecución del programa.
 |
| Ilustración 8: Error durante el análisis al no encontrar una coma en una instrucción INPUT. |
 |
| Ilustración 9: Error por declarar una variable con un identificador no válido. |
 |
| Ilustración 10: Error al operar con una variable no declarada con anterioridad. |
En este último ejemplo se puede observar un error de análisis, no de ejecución. Esto es así porque se analiza línea a línea y después se ejecuta la línea previamente analizada. En este caso en la línea 7 se hace uso de una variable no declarada con DIM previamente. También daría error si se trabaja con una variable sin haberla inicializado antes mediante una expresión y el comando LET o a través de un valor leído con INPUT por teclado.
Implementación.
A la hora de abordar la práctica ésta se dividió en 4 partes de forma general:
- Interfaz de fichero: Clase encargada de obtener todo el contenido de un fichero a partir de una ruta absoluta o relativa para volcar el contenido de éste si existe y se puede leer. Su contenido será utilizado posteriormente por el analizador.
- Intérprete de BASIC: Es la fachada que separa el intérprete propiamente dicho de las interfaces. En este caso de la interfaz de fichero, ya que de usuario no hay, siendo la ruta del fichero del código fuente la única interacción del intérprete con el usuario (salvo el propio programa BASIC interpretado). Esta clase tiene todas las operaciones que son públicas y generales al intérprete y al analizador, como por ejemplo interpretar un programa.
- Analizador: Clase que, a partir de un programa escrito BASIC, lo analiza léxica y sintácticamente línea a línea informando de cualquier error. Si todo está bien, se comunica con el modelado del programa para que éste cree una nueva instrucción y después la interprete (ejecute).
- Modelado del programa: Como su nombre implica, es un modelado del concepto de programa interpretado en sí. La aproximación consiste en tener un conjunto de variables e instrucciones que formen parte de un programa. De este modo, la clase Programa es un contenedor de variables e instrucciones, que posee un contador de programa el cual indica qué instrucción se va a ejecutar ya que puede haber saltos en la ejecución secuencial del programa.
Se ha utilizado memoria dinámica para almacenar las variables y las instrucciones, ya que es lo más adecuado ya que se van creando en tiempo de ejecución. La mayoría de las funciones miembro de estas clases son inline (a través de los correspondientes ficheros de cabecera) porque los intérpretes suelen ser lentos y compensa sacrificar algo de memoria si con ello se consigue una mayor rapidez a la hora de interpretar el programa BASIC.
Uno de los aspectos significativos es que no se utilizó el patrón interpreter. En el diseño inicial que realicé constaba este patrón para ir analizando qué tokens se corresponden con miembros terminales y no terminales de la gramática del lenguaje. El patrón está bien para gramáticas pequeñas como una calculadora polaca inversa o conversión de números romanos, pero al tener una gramática con tantas reglas su complicación crecía de forma potencial y se volvía impracticable. Se perdió bastante tiempo con esta aproximación hasta que se eligió implementar el analizador por una parte (consumiendo el contenido del programa mediante comparaciones y expresiones regulares POSIX extendidas) y por otra un fiel reflejo de un programa en sí. En esto último se trata de simular la realidad viendo un programa como una lista en principio secuencial de instrucciones que se ejecutan en base a un contador de programa (en este caso es un contador virtual, no físico en la CPU) y que tienen acceso a una serie de variables para operar.
Como el intérprete puede dar una cantidad de errores muy específicos (errores en tiempo de ejecución, errores léxicos y sintácticos) se utilizó la gestión de errores mediante el manejo de excepciones. También se capturan excepciones desconocidas por si surge cualquier error no localizado y/o desconocido durante la etapa de desarrollo. Es importante saber que, tras cualquier error la ejecución del programa finaliza, pero siempre de forma controlada y si el error tiene que ver con el proceso de análisis o de ejecución se mostrará junto al error una descripción lo más detallada posible.
Con el objetivo de conseguir un código fuente lo mejor estructurado posible
se ha seguido una guía de estilo o estandarizado de código. Dicha guía se ha seguido siempre que ha sido posible, ya que existen instrucciones bastante largas que, por mucho que se estructuren en varias líneas, pierden legibilidad.
Los comentarios se realizaron principalemente a nivel de clase, funciones miembros y datos miembros, siguiendo los comentarios de tipo JAVADOC para que en caso de que proceda, realizar una documentación exhaustiva con Doxygen. Se utilizaron comentarios tradicionales para comentar ciertas partes de código en aras de una mayor comprensión.
Diagrama de clases UML.
El modelado de clases es el siguiente, el cual intenta simular el programa con sus instrucciones y variables que se ejecutan secuencialmente segun van siendo analizadas una a una, hasta que se produzca un salto, el fin de programa o un error. En este último caso se aborta la ejecución del intérprete y se muestra la descripción del error y el origen (si procede) al usuario por pantalla.
 |
| Ilustración 11: Diagrama de clases del intérprete BASIC. |
Diagrama de secuencia UML.
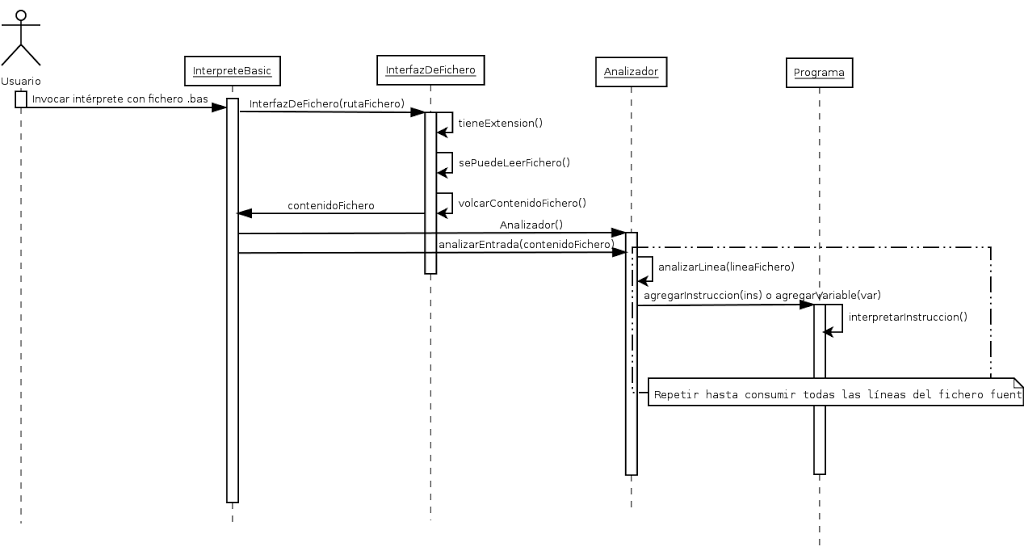
El diagrama de secuencia general del sistema a la hora de interpretar un programa es el siguiente:
 |
| Ilustración 12: Diagrama de secuencia general del intérprete BASIC. |
Código fuente.
analizador.h
#ifndef Analizador_h
#define Analizador_h
#include "programa.h"
#include <string>
#include <sstream>
/// Analizador léxico y sintáctico.
class Analizador {
public:
/** El constructor crea en memoria dinámica la representación del
programa (con sus variables e instrucciones) e inicializa el
contador de líneas. */
Analizador( )
{
this->contadorDeLineas = 0;
};
/** Analiza una entrada proporcionada que contenga todas las
instrucciones del programa BASIC a interpretar, subdividiendolas
líneas.
@param El código del programa con sus saltos de línea. */
void analizarEntrada( std::string &lineasPrograma );
~Analizador( ) { };
private:
/** Analiza léxica y sintácticamente una linea de código BASIC,
teniendo en cuenta las líneas anteriores (etiquetas, variables,
etc...).
@param La línea de programa a analizar. */
void analizarLinea( std::string &lineaPrograma );
/** Comprueba si un identificador es correcto en BASIC siguiendo la
regla id ::= [a-z]+ de la gramática.
@param El identificador de una variable.
@return TRUE si el nombre válida contra la regex [a-z]+, FALSE
en cualquier otro caso. */
bool esIdentificadorCorrecto( const std::string &id ) const;
/** Comprueba una cadena pasada como argumento a una instrucción BASIC.
@param Una cadena argumento de una instrucción BASIC (con comillas
incluidas).
@return TRUE si la cadena está bien escrita y delimitada y FALSE en
caso contrario. */
bool esCadenaCorrecta( const std::string &cadena ) const;
bool esExpresionCorrecta( const std::string &exp ) const;
/** Simplifica el manejo de errores del analizador, lanzando la
excepción que corresponda añadiendo el número de línea en que
se encuentra el error.
@param Descripción de la excepción o error. */
void error ( const std::string &e ) const;
Programa programaActual;
unsigned long contadorDeLineas;
};
#endif
analizador.cpp
#include "analizador.h"
#include "variableEntera.h"
#include "instruccion.h"
#include "instruccionREM.h"
#include "instruccionDIM.h"
#include "instruccionGOTO.h"
#include "instruccionINPUT.h"
#include "instruccionPRINT.h"
#include "instruccionLET.h"
#include <iostream>
#include <regex.h>
void Analizador::analizarEntrada( std::string &lineasPrograma )
{
unsigned int posicionFinLinea;
std::string lineaActual;
while ( lineasPrograma.length() != 0 ) {
posicionFinLinea = lineasPrograma.find_first_of( 'n' );
if ( posicionFinLinea != std::string::npos ) {
lineaActual = lineasPrograma.substr( 0, posicionFinLinea );
this->contadorDeLineas++;
analizarLinea( lineaActual );
lineasPrograma = lineasPrograma.substr( posicionFinLinea + 1,
lineasPrograma.length( ) - 1);
this->programaActual.interpretarInstruccion( );
} else {
/* Caso en que la última línea del programa
no termine con salto de línea. */
this->contadorDeLineas++;
analizarLinea( lineasPrograma );
lineasPrograma.clear();
}
}
}
void Analizador::analizarLinea( std::string &lineaPrograma )
{
std::string etiqueta = "";
std::string comando = "";
std::string identificadorVariable = "";
std::string cadena = "";
Instruccion * nuevaInstruccion;
bool lineaProcesada = false;
// Se idenfica la posible etiqueta:
if ( lineaPrograma[ 0 ] == ':' ) {
if ( lineaPrograma.find_first_of( ' ' ) == std::string::npos ) {
error( "Etiqueta incorrecta." );
} else {
etiqueta = lineaPrograma.substr( 1, lineaPrograma.find_first_of( ' ' ) - 1 );
lineaPrograma.erase( 0, lineaPrograma.find_first_of( ' ' ) + 1 );
}
}
// Se identifica la posible instrucción BASIC:
if ( lineaPrograma.length() >= 3 ) {
comando = lineaPrograma.substr( 0, 3 );
/* La línea se ignora por completo (salvo
si posee etiqueta, entonces se
almacenará junto al resto de instrucciones). */
if ( comando.compare( "REM" ) == 0 ) {
lineaPrograma.erase( 0, 3 );
if ( lineaPrograma.length( ) == 0 || lineaPrograma[ 0 ] == ' ' ) {
if ( etiqueta.compare( "" ) != 0 ) {
// Se crea y se añade la instrucción analizada:
nuevaInstruccion = new InstruccionREM( etiqueta );
this->programaActual.agregarInstruccion( nuevaInstruccion );
}
lineaProcesada = true;
}
}
/* DIM declara una nueva variable. Si la variable se
encuentra ya declarada se ignora. */
if ( comando.compare( "DIM" ) == 0 ) {
lineaPrograma.erase( 0, 3 );
if ( lineaPrograma.length( ) > 0 ) {
if ( lineaPrograma[ 0 ] == ' ' ) {
if ( lineaPrograma.length( ) > 0 ) {
lineaPrograma.erase( 0, 1 );
// Comprobamos el identificador de variable:
if ( this->esIdentificadorCorrecto( lineaPrograma ) ) {
if ( !this->programaActual.existeLaVariable( lineaPrograma ) ) {
// Se añade la variable.
Variable * nuevaVariable = new VariableEntera( lineaPrograma );
this->programaActual.agregarVariable(nuevaVariable);
}
// Se crea y se añade la instrucción analizada:
nuevaInstruccion = new InstruccionDIM( etiqueta, lineaPrograma, this->programaActual );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
error( "Identificador de variable no válido.");
}
} else {
error( "Identificador sin declarar." );
}
} else {
error( "Error de sintaxis, comando desconocido." );
}
} else {
error( "Instrucción incompleta." );
}
}
/* LET permite asignar un valor a una variable
previamente declarada a partir de una
expresión. */
if ( comando.compare( "LET" ) == 0 ) {
lineaPrograma.erase( 0, 3 );
if ( lineaPrograma.length( ) > 0
&& lineaPrograma[ 0 ] == ' ' ) {
lineaPrograma.erase( 0, 1 );
if ( lineaPrograma.length( ) > 0 ) {
if ( lineaPrograma.find_first_of( ' ' ) != std::string::npos ) {
identificadorVariable = lineaPrograma.substr( 0, lineaPrograma.find_first_of( ' ' ) );
// Se comprueba el identificador de la variable:
if ( this->esIdentificadorCorrecto( identificadorVariable ) ) {
// Se comprueba que la variable exista:
if ( this->programaActual.existeLaVariable( identificadorVariable ) ) {
lineaPrograma.erase( 0, identificadorVariable.length( ) );
// Se comrprueba el operador de asignación:
if ( lineaPrograma.length( ) > 3 ) {
std::string operadorAsignacion = lineaPrograma.substr( 0, 3 );
if ( operadorAsignacion.compare( " = " ) == 0 ) {
lineaPrograma.erase( 0 , 3 );
/* Se comprueba la existencia de la expresión de
asignación. */
if ( lineaPrograma.length( ) > 0 ) {
// Se comprueba que la expresión sea válida:
if ( this->esExpresionCorrecta( lineaPrograma ) ) {
nuevaInstruccion = new InstruccionLET( etiqueta, identificadorVariable, lineaPrograma, programaActual );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
error( "Expresión incorrecta tras operador de asignación '='." );
}
} else {
error( "Expresión tras operador de asignación '=' no encontrada." );
}
} else {
error( "Operador de asignación '=' no encontrado." );
}
} else {
error( "Faltan el operador de asignación y la expresión de asignación." );
}
} else {
error( "Uso de variable no declarada previamente." );
}
} else {
error( "Identificador de variable no válido." );
}
} else {
error( "Falta la expresión de asignación." );
}
} else {
error( "Faltan el identificador de variable y la expresión de asignación." );
}
}
}
}
if ( lineaPrograma.length( ) >= 4 ) {
comando = lineaPrograma.substr( 0, 4 );
/* Instrucción GOTO de salto incondicional,
la cual dada una etiqueta, redirige el
flujo secuencial del programa a la
instrucción que la tenga. */
if ( comando.compare( "GOTO" ) == 0 ) {
lineaPrograma.erase( 0, 4 );
if ( lineaPrograma.length( ) > 0 ) {
if ( lineaPrograma[ 0 ] == ' ' ) {
lineaPrograma.erase( 0, 1 );
if ( lineaPrograma.length( ) > 0 ) {
if ( this->esIdentificadorCorrecto( lineaPrograma ) ) {
if ( this->programaActual.existeLaEtiqueta( lineaPrograma ) ) {
// Se crea y se añade la instrucción analizada:
nuevaInstruccion = new InstruccionGOTO( etiqueta, lineaPrograma, this->programaActual );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
error( "La etiqueta referenciada no fue definida anteriormente." );
}
} else {
error( "Identificador de etiqueta no válido." );
}
} else {
error( "No encontrada etiqueta destino en la instrucción de salto incondicional GOTO." );
}
}
}
}
}
if ( lineaPrograma.length( ) >= 5 ) {
comando = lineaPrograma.substr( 0, 5 );
/* PRINT muestra un mensaje por consola y, opcionalmente,
el valor de una variable. Si no recibe ningún parámetro,
la instrucción imprime un salto de línea en consola. */
if ( comando.compare( "PRINT" ) == 0 ) {
lineaPrograma.erase( 0, 5 );
// Instrucción PRINT sin argumentos:
if ( lineaPrograma.length( ) == 0 ) {
// Crear instruccion PRINT sin argumentos:
nuevaInstruccion = new InstruccionPRINT( this->programaActual, etiqueta );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
// PRINT con argumentos:
lineaPrograma.erase( 0, 1 );
if ( lineaPrograma.length( ) >= 2
&& lineaPrograma.find_last_of( '"' ) != std::string::npos ) {
if ( this->esCadenaCorrecta( lineaPrograma ) ){
/* Se comprueba si sólo hay una cadena o
también un identificador de una variable. */
cadena = lineaPrograma.substr( lineaPrograma.find_first_of( '"' ) + 1, lineaPrograma.find_last_of( '"' ) - 1 );
lineaPrograma.erase( 0, lineaPrograma.find_last_of( '"' ) + 1 );
if ( lineaPrograma.length( ) == 0 ) {
// Añadir instrucción PRINT con cadena.
nuevaInstruccion = new InstruccionPRINT( this->programaActual, etiqueta, cadena );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
if ( lineaPrograma.length( ) > 0
&& lineaPrograma[ 0 ] == ',' ) {
lineaPrograma.erase( 0, 1 );
if (lineaPrograma.length( ) > 1 ) {
lineaPrograma.erase( 0, 1 );
if ( this->esIdentificadorCorrecto(lineaPrograma) ) {
if ( this->programaActual.existeLaVariable( lineaPrograma ) ) {
// Se registra la instrucción PRINT con cadena y variable:
nuevaInstruccion = new InstruccionPRINT( this->programaActual, etiqueta, cadena, lineaPrograma );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
error( "Uso de variable no declarada previamente." );
}
} else {
error( "Identificador de variable no válido." ) ;
}
}
} else {
error( "Falta la coma ',' tras la cadena." );
}
}
}
}
}
}
/* Se analiza la instrucción BASIC INPUT, la cual
permite leer por teclado el valor de un dato
después de mostrar un mensaje por pantalla. */
if ( comando.compare( "INPUT" ) == 0 ) {
lineaPrograma.erase( 0, 5 );
if ( lineaPrograma.length( ) > 0 ) {
if ( lineaPrograma[ 0 ] == ' ' ) {
lineaPrograma.erase( 0, 1 );
// Se detecta la cadena de la instrucción:
if ( lineaPrograma.length( ) >= 2
&& lineaPrograma.find_last_of( '"' ) != std::string::npos ) {
cadena = lineaPrograma.substr( 0, lineaPrograma.find_last_of( '"' ) + 1 );
// Se valida:
if ( this->esCadenaCorrecta( cadena ) ) {
lineaPrograma.erase( 0, cadena.length( ) );
if ( lineaPrograma.length( ) > 0
&& lineaPrograma[ 0 ] == ',' ) {
lineaPrograma.erase( 0, 1 );
if ( lineaPrograma.length( ) > 0
&& lineaPrograma[ 0 ] == ' ' ) {
lineaPrograma.erase( 0, 1 );
// Se comprueba el identificador de la variable:
if ( this->esIdentificadorCorrecto( lineaPrograma ) ) {
// Se comprueba que el identificador existe:
if ( this->programaActual.existeLaVariable( lineaPrograma ) ) {
// Se crea y se añade la instrucción analizada:
cadena = cadena.substr( 1, cadena.length() - 2 );
nuevaInstruccion = new InstruccionINPUT( this->programaActual, etiqueta, cadena, lineaPrograma );
this->programaActual.agregarInstruccion( nuevaInstruccion );
lineaProcesada = true;
} else {
error( "La variable no ha sido declara previamente." );
}
} else {
error( "Identificador de variable no válido." ); //ERROR SALTA AKI
}
} else {
error( "Falta identificador de variable." );
}
} else {
error( "Falta la coma ',' tras la cadena." );
}
} else {
error( "Cadena no válida." );
}
} else {
error( "Falta la cadena como argumento de la instrucción INPUT." );
}
}
} else {
error( "Faltan la cadena de caracteres y el identificador de la variable." );
}
} else {
// Error de sintaxis, instrucción desconocida en la línea.
if ( lineaProcesada == false ) {
error( "Instrucción desconocida." );
}
}
}
}
bool Analizador::esIdentificadorCorrecto ( const std::string &id ) const
{
regex_t regex;
int retint;
std::string error = "No se pudo compilar la expresión regular.";
// Se compila la expresión regular:
retint = regcomp( ®ex, "^[a-z]+$", REG_EXTENDED );
if( retint ){ // Lanzar error
throw error;
}
// Se compara el lenguaje de la expresión regular:
retint = regexec( ®ex, id.c_str(), 0, NULL, 0 );
if( !retint )
return true;
else
return false;
}
bool Analizador::esCadenaCorrecta ( const std::string &cadena ) const
{
if ( cadena.find_first_of( '"' ) != std::string::npos
&& cadena.find_last_of( '"' ) != std::string::npos ) {
int principio = cadena.find_first_of( '"' );
int fin = cadena.find_last_of( '"' );
if ( principio < fin ) return true;
}
return false;
}
bool Analizador::esExpresionCorrecta( const std::string &exp ) const
{
regex_t regex;
int retint;
std::string copiaExp = exp;
std::string error = "No se pudo compilar la expresión regular.";
// Se compila la expresión regular:
retint = regcomp( ®ex, "^([0-9]+|[a-z]+)( [*+-/] ([0-9]+|[a-z]+))*$", REG_EXTENDED );
if( retint ){
throw error;
}
// Se compara el lenguaje de la expresión regular:
retint = regexec( ®ex, exp.c_str(), 0, NULL, 0 );
/* Se comprueban los identificadores, pues deben ser de variables
que existan: */
while ( copiaExp.length( ) != 0 ) {
std::string palabra = "";
if ( copiaExp.find_first_of( ' ' ) != std::string::npos )
palabra = copiaExp.substr( 0, copiaExp.find_first_of( ' ' ) + 1 );
else
palabra = copiaExp;
if ( this->esIdentificadorCorrecto( palabra ) ) {
if ( !this->programaActual.existeLaVariable( palabra ) ) {
error = "Identificador de variable no declarada en expresión.";
this->error( error );
}
}
copiaExp.erase( 0, palabra.length( ) );
}
if( !retint )
return true;
else
return false;
}
void Analizador::error ( const std::string &e ) const {
std::ostringstream oss;
oss << e << " Línea: " << this->contadorDeLineas;
throw oss.str( );
}
instruccion.h
#ifndef Instruccion_h
#define Instruccion_h
#include <string>
/// Instrucción ejecutable que puede tener etiqueta que la referencie (o no).
class Instruccion {
public:
/** Como una instrucción puede no hacer nada, lo indispensable a la
hora de instanciarla es que pueda tener una etiqueta. */
Instruccion( const std::string &e = "" ) : etiqueta( e ) { };
/// Una instrucción tiene que poder ejecutarse.
virtual void ejecutar() = 0;
const std::string &getEtiqueta( ) const
{ return this->etiqueta; }
virtual ~Instruccion( ) { };
private:
std::string etiqueta;
};
#endif
instruccionDIM.h
#ifndef InstruccionDIM_h
#define InstruccionDIM_h
#include "instruccion.h"
#include "programa.h"
#include "variableEntera.h"
class InstruccionDIM : public Instruccion {
public:
InstruccionDIM( const std::string &etiqueta, const std::string &var
, Programa &p ) : Instruccion ( etiqueta ),
nombreVariable( var ),
programa( p ) { };
void ejecutar( )
{ /* Nada que hacer. */ };
~InstruccionDIM( ) { };
private:
std::string nombreVariable;
Programa programa;
};
#endif
instruccionGOTO.h
#ifndef InstruccionGOTO_h
#define InstruccionGOTO_h
#include "instruccion.h"
#include "programa.h"
class InstruccionGOTO : public Instruccion {
public:
InstruccionGOTO( const std::string &etiqueta,
const std::string &etiquetaDeSalto, Programa &p )
: Instruccion( etiqueta ) {
etiquetaDestino = etiquetaDeSalto;
programa = p;
};
void ejecutar( )
{
unsigned long posicion;
posicion = programa.getPosicionInstruccion( etiquetaDestino );
this->programa.saltar( posicion );
};
~InstruccionGOTO( ) { };
private:
std::string etiquetaDestino;
Programa programa;
};
#endif
instruccionINPUT.h
#ifndef InstruccionINPUT_h
#define InstruccionINPUT_h
#include "instruccion.h"
#include "programa.h"
class InstruccionINPUT : public Instruccion {
public:
InstruccionINPUT( Programa &p, const std::string &etiqueta,
const std::string &c = "", const std::string &var = "" )
: Instruccion ( etiqueta ),
programa( p ),
variable( var ),
cadena( c ) { };
void ejecutar( )
{
int buffer = 0;
VariableEntera * var;
std::string error = "Error en tiempo de ejecución: ";
error.append( "lectura de valor erróneo de teclado." );
std::cout << this->cadena;
std::cin >> buffer;
if ( std::cin.fail( ) ) throw error;
var = dynamic_cast ( programa.getVariable( variable ) );
var->setValor( buffer );
};
~InstruccionINPUT( ) { };
private:
Programa programa;
std::string variable;
std::string cadena;
};
#endif
instruccionLET.h
#ifndef InstruccionLET_h
#define InstruccionLET_h
#include "instruccion.h"
#include "programa.h"
#include <regex.h>
#include <sstream>
class InstruccionLET : public Instruccion {
public:
InstruccionLET( const std::string &etiqueta, const std::string &var,
const std::string &e, Programa &p ) : Instruccion ( etiqueta ) {
variable = var;
expresion = e;
programa = p;
};
void ejecutar( )
{
char operacion = ' ';
std::string exp = this->expresion;
std::string palabra;
regex_t regex;
int retint;
std::string error = "No se pudo compilar la expresión regular.";
unsigned int iteracion = 0;
int resultado = 0;
VariableEntera * var;
// Se compila la expresión regular:
retint = regcomp( ®ex, "^[a-z]+$", REG_EXTENDED );
if( retint ) throw error;
while ( exp.length( ) != 0 ) {
palabra = "";
if ( exp.find_first_of( ' ' ) != std::string::npos ) {
palabra = exp.substr( 0, exp.find_first_of( ' ' ) );
exp.erase( 0, palabra.length( ) + 1 );
} else {
palabra = exp;
exp.erase( 0, palabra.length( ) );
}
/* Cada palabra puede ser un identificador, una constante
numérica o un operador. */
// Se compara el lenguaje de la expresión regular:
retint = regexec( ®ex, palabra.c_str(), 0, NULL, 0 );
if( !retint ) {
var = dynamic_cast ( programa.getVariable( palabra ) );
// Se comprueba que la variable está inicializada:
if ( !var->fueInicializada( ) ) {
error = "Error en tiempo de ejecución. Variable no inicializada: ";
error.append( var->getIdentificador( ) );
throw error;
}
if ( iteracion == 0 ) {
resultado = var->getValor( );
} else {
// Se opera en base al operador anterior:
switch ( operacion ) {
case '+': resultado += var->getValor( );
break;
case '-': resultado -= var->getValor( );
break;
case '*': resultado *= var->getValor( );
break;
case '/': if ( var->getValor( ) == 0 ) {
error = "Error en tiempo de ejecución.";
error.append( " División entre cero." );
throw error;
}
resultado /= var->getValor( );
};
}
} else {
switch ( palabra[ 0 ] ) {
case '+': operacion = '+';
break;
case '-': operacion = '-';
break;
case '*': operacion = '*';
break;
case '/': operacion = '/';
break;
default:
// Se trata de un entero.
int entero = 0;
// Se convierte la palabra a entero:
std::istringstream ss( palabra );
ss >> entero;
if ( iteracion == 0 ) {
resultado = entero;
} else {
// Se opera en base al operador anterior:
switch ( operacion ) {
case '+': resultado += entero;
break;
case '-': resultado -= entero;
break;
case '*': resultado *= entero;
break;
case '/': if ( entero == 0 ) {
error = "Error en tiempo de ejecución.";
error.append( " División entre cero." );
throw error;
}
resultado /= entero;
};
}
};
}
iteracion++;
}
var = dynamic_cast ( programa.getVariable( variable ) );
var->setValor( resultado );
std::cout << this->variable
<< " vale: "
<< var->getValor()
<< std::endl;
};
~InstruccionLET( ) { };
private:
std::string variable;
std::string expresion;
Programa programa;
};
#endif
instruccionPRINT.h
#ifndef InstruccionPRINT_h
#define InstruccionPRINT_h
#include "instruccion.h"
#include <iostream>
#include "programa.h"
class InstruccionPRINT : public Instruccion {
public:
InstruccionPRINT( Programa &p, const std::string &etiqueta,
const std::string &cadena = "", const std::string &var = "" )
: Instruccion ( etiqueta ), programa( p ), cadenaDeTexto( cadena ),
variable( var ) { };
void ejecutar( )
{
VariableEntera * var;
if ( this->variable.compare( "" ) == 0 ) {
std::cout << cadenaDeTexto << std::endl;
} else {
var = dynamic_cast ( programa.getVariable( variable ) );
std::cout << cadenaDeTexto << var->getValor() << std::endl;
}
};
~InstruccionPRINT( ) { };
private:
Programa programa;
std::string cadenaDeTexto;
std::string variable;
};
#endif
instruccionREM.h
#ifndef InstruccionREM_h
#define InstruccionREM_h
#include "instruccion.h"
#include <iostream>
class InstruccionREM : public Instruccion {
public:
InstruccionREM( const std::string &etiqueta ) : Instruccion ( etiqueta ) { };
void ejecutar( )
{ /* Nada que hacer */ };
~InstruccionREM( ) { };
};
#endif
interfazDeFichero.h
#ifndef InterfazDeFichero_h
#define InterfazDeFichero_h
#include lt;string>
class InterfazDeFichero {
public:
InterfazDeFichero( char * ruta ) : rutaAlFichero( ruta ) { };
bool tieneExtension() const;
bool sePuedeLeerFichero() const;
std::string volcarContenidoFichero() const;
std::string getRuta() const;
~InterfazDeFichero() { };
private:
char * rutaAlFichero;
};
#endif
interfazDeFichero.cpp
#include <fstream>
#include <sstream>
#include "interfazDeFichero.h"
#include <regex.h>
/* Función miembro que comprueba si el fichero
de texto con las instrucciones BASIC es
accesible. */
bool InterfazDeFichero::sePuedeLeerFichero() const
{
std::ifstream fichero( rutaAlFichero );
if ( fichero.is_open() ) {
fichero.close();
return true;
}
return false;
}
/* Comprueba que la extensión del fichero
sea correcta (.BAS o .bas). */
bool InterfazDeFichero::tieneExtension() const
{
regex_t regex;
int retint;
std::string error;
// Se compila la expresión regular:
retint = regcomp( ®ex, ".[bB][aA][sS]$", 0 );
if( retint ){ // Lanzar error
error = "No se pudo compilar la expresión regular.";
throw error;
}
// Se compara el lenguaje de la expresión regular:
retint = regexec( ®ex, this->rutaAlFichero, 0, NULL, 0 );
if( !retint )
return true;
else
return false;
}
/* A partir de un fichero de texto, se devuelve todo
su contenido en cadena de texto. */
std::string InterfazDeFichero::volcarContenidoFichero() const
{
std::ostringstream toret;
std::string linea;
std::ifstream fichero( rutaAlFichero );
if ( fichero.is_open() ) {
getline( fichero, linea, 'n' );
while( !fichero.eof() ) {
toret << linea << 'n';
getline( fichero, linea, 'n' );
}
}
return toret.str();
}
/* Retorna la ruta al fichero de código fuente. */
std::string InterfazDeFichero::getRuta() const
{ return this->rutaAlFichero; }
interpreteBasic.h
#ifndef InterpreteBasic_h
#define InterpreteBasic_h
#include <string>
#include "interfazDeFichero.h"
#include "analizador.h"
/** Clase que hace de fachada de la lógica de implementación del intérprete.
Las distintas interfaces trabajan contra ella. */
class InterpreteBasic {
public:
/** Método constructor de la clase InterpreteBasic.
@param Ruta del fichero que contiene el código fuente en cadena
caracteres de C. */
InterpreteBasic( char * rutaFicheroAInterpretar ) : interfazFichero( rutaFicheroAInterpretar )
{ analizador = Analizador(); };
/** Función que orquesta el resto de clases, para
* obtener las instrucciones del fichero, analizarlas
* y ejecutarlas una a una. */
void ejecutar();
~InterpreteBasic() { };
private:
InterfazDeFichero interfazFichero;
Analizador analizador;
};
#endif
interpreteBasic.cpp
#include "interpreteBasic.h"
#include <iostream>
void InterpreteBasic::ejecutar( )
{
std::string contenidoFichero;
std::string error;
// Se comprueba que se puede acceder al fichero:
try {
std::cout << "Comprobando acceso al fichero... ";
if ( this->interfazFichero.sePuedeLeerFichero( ) ) {
std::cout << "OKn";
// Se comprueba la extensión del fichero:
if ( this->interfazFichero.tieneExtension( ) ) {
// Se obtiene el contenido del fichero:
contenidoFichero = interfazFichero.volcarContenidoFichero();
// Se procede a analizar e interpretar los comandos:
this->analizador.analizarEntrada( contenidoFichero );
} else {
error = "El fichero no tiene extensión .bas";
throw error;
}
} else {
error = "nNo se puede leer el contenido del fichero. Compruebe ruta y permisos.";
throw error;
}
}
catch ( const std::string &e ) {
std::cerr << "ERROR: "
<< e
<< "nSaliendo..."
<< std::endl;
}
catch ( ... ) {
std::cerr << "ERROR desconocido."
<< "nSaliendo..."
<< std::endl;
}
}
/// Programa principal
int main( int argc, char * argv[] )
{
InterpreteBasic * interprete;
std::cout << "BASIC interpreter" << std::endl;
switch( argc ){
// El programa no recibió ningún parámetro.
case 1: std::cout << "ERROR: No se ha pasado la ruta del fichero de "
<< "código fuente como parámetro." << std::endl;
std::cout << "Abortando..." << std::endl;
break;
// El programa recibe como parámetro un fichero .bas //FALTAA COMPROBAR LA EXTENSION DEL FOCHEROOOOO!!!
case 2: interprete = new InterpreteBasic( argv[ 1 ] );
interprete->ejecutar();
break;
// Se ignoran el resto de parámetros, considerando válido sólo el primero.
default:std::cout << "ADVERTENCIA: Se ignorarán los parámetros "
<< "que sigan al primero..."
<< std::endl;
interprete = new InterpreteBasic( argv[ 1 ] );
interprete->ejecutar();
}
return 0;
}
programa.h
#ifndef Programa_h
#define Programa_h
#include <vector>
#include "variable.h"
#include "variableEntera.h"
#include "instruccion.h"
#include "instruccionREM.h"
#include <iostream>
/** Abstracción del programa BASIC analizado con el analizador.
Puede verse también como un clase contenedor de variables
e instrucciones. */
class Programa {
public:
/// Se inicializa el contador de programa.
Programa( )
{ this->contadorDePrograma = 0; };
/** Como el programa es interpretado, se puede añadir una nueva
instrucción en tiempo de ejecución.
@param Dirección de memoria de la instrucción ya creada en
el heap. */
void agregarInstruccion( Instruccion * i )
{ this->instrucciones.push_back( i ); };
/** Como el programa es interpretado, se puede añadir una nueva
variable en tiempo de ejecución.
@param Dirección de memoria de la variable ya creada en el heap. */
void agregarVariable( Variable * v )
{ this->variables.push_back( v ); };
/** Debido a las sentencias de decisión y de salto el flujo lineal de
ejecución varía. Esto es: cambia el número de instrucción a
ejecutar y se cambia el contador de programa.
@param Posición de la instrucción siguiente a ejecutar. */
void setContadorDePrograma( unsigned long nuevoValor )
{ this->contadorDePrograma = nuevoValor; }
/** A través del contador de programa, se ejecuta la instrucción
que corresponda. */
void interpretarInstruccion( )
{
if ( !this->instrucciones.empty( ) ) {
this->instrucciones[ this->contadorDePrograma++ ]->ejecutar( );
}
};
/** Comprueba la existencia de una variable previamente declarada.
@param Identificador de la variable a buscar.
@return TRUE si ya fue declarada, FALSE si no. */
bool existeLaVariable( const std::string &variableABuscar ) const;
/** Comprueba si una etiqueta ya existe.
@param Nombre de la etiqueta (sin los dos puntos ':').
@return TRUE si la etiqueta existe o FALSE si no. */
bool existeLaEtiqueta( const std::string &etiquetaABuscar ) const;
/** Proporciona la posición de una instrucción a partir de su etiqueta.
@param Etiqueta a buscar.
@return Posición de la instrucción con la etiqueta buscada. */
unsigned long getPosicionInstruccion
( const std::string &etiquetaABuscar ) const;
/** Como la representación con objetos del programa existe en el heap,
se borran todas las instrucciones y variables creadas tras el
proceso de análisis. */
~Programa( )
{
if ( !this->variables.empty() )
for ( unsigned int i = 0; i < this->variables.size(); i++ )
delete this->variables[ i ];
if ( !this->instrucciones.empty() )
for ( unsigned int i = 0; i < this->instrucciones.size(); i++ )
delete this->instrucciones[ i ];
};
/** Busca una variable declarada en el heap.
@param El identificador de la variable a coger.
@return Dirección de memoria de la variable. */
Variable * getVariable( const std::string &id) const;
/** Invocado durante una instrucción de salto, recorre las instrucciones
anteriores desde la posición indicada.
@param La posición de la instrucción a que saltar ( de 0 a N). */
void saltar( unsigned long c );
private:
std::vector variables;
std::vector instrucciones;
unsigned long contadorDePrograma;
};
#endif
programa.cpp
#include "programa.h"
#include <vector>
#include "variable.h"
#include "variableEntera.h"
#include "instruccion.h"
#include "instruccionREM.h"
#include <iostream>
bool Programa::existeLaVariable( const std::string &variableABuscar ) const
{
std::string variable;
if ( !this->variables.empty( ) ) {
for ( unsigned int i = 0; i < this->variables.size( ); i++ ) {
variable = this->variables[ i ]->getIdentificador( );
if ( variableABuscar.compare( variable ) == 0 )
return true;
}
}
return false;
};
bool Programa::existeLaEtiqueta( const std::string &etiquetaABuscar ) const
{
std::string etiqueta;
if ( !this->instrucciones.empty( ) ) {
for ( unsigned int i = 0; i < this->instrucciones.size( ); i++ ) {
etiqueta = this->instrucciones[ i ]->getEtiqueta( );
if ( etiqueta.compare( etiquetaABuscar ) == 0 )
return true;
}
}
return false;
};
unsigned long Programa::getPosicionInstruccion ( const std::string &etiquetaABuscar ) const
{
std::string etiqueta;
if ( !this->instrucciones.empty( ) ) {
for ( unsigned int i = 0; i < this->instrucciones.size( ); i++ ) {
etiqueta = this->instrucciones[ i ]->getEtiqueta( );
if ( etiqueta.compare( etiquetaABuscar ) == 0 )
return i;
}
}
return -1;
}
Variable * Programa::getVariable( const std::string &id) const
{
std::string variable;
for ( unsigned int i = 0; i < this->variables.size( ); i++ ) {
variable = variables[ i ]->getIdentificador();
if ( variable.compare( id ) == 0 )
return variables[ i ];
}
}
void Programa::saltar( unsigned long c )
{
std::cout << "SALTANDO.." << std::endl;
/* Como hubo un salto se ejecutan el resto de instrucciones
hasta volver a la última. */
do {
this->instrucciones[ c ]->ejecutar();
c++;
} while ( c < this->contadorDePrograma );
};
variable.h
#ifndef VariableEntera_h
#define VariableEntera_h
#include "variable.h"
/// Subclase de Variable que representa al típo de dato básico entero de BASIC.
class VariableEntera : public Variable {
public:
/** Instancia una variable nueva de tipo entero.
@param Identificador de la nueva variable. */
VariableEntera( const std::string &id ) : Variable( id ) { };
/** Inicializa el contenido de la variable.
@param El valor entero a asignar la variable. */
void setValor( int v )
{
this->valor = v;
Variable::setInicializada( true );
};
int getValor( ) const
{
std::string error;
if ( this->fueInicializada() ) {
return this->valor;
} else {
error = "Variable declarada pero no inicializada.";
throw error;
}
};
~VariableEntera( ) { };
private:
int valor;
};
#endif
Posibles ampliaciones y mejoras.
Se pueden implementar una serie de mejoras que hagan pie en la naturaleza de intérprete del lenguaje, como pueden ser interpretar código distribuido en distintos ficheros fuente y mejorar la rapidez y eficiencia del intérprete, ya que habitualmente estos son mucho más lentos que los compiladores.
Por último, sería interesante modificar el analizador para que obvie las indentaciones, los espacios extras vacíos y soporte identificadores más tradicionales como los de la mayoría de lenguajes de programación. Es decir; que se puedan validar contra una expresión regular del tipo ^[a-zA-Z_][a-zA-Z_0-9]*$.